Creating an evaluation
To create an evaluation, head over to the evaluations section in the Datawizz dashboard. Here you can create a new evaluation by clicking the “New Evaluation” button.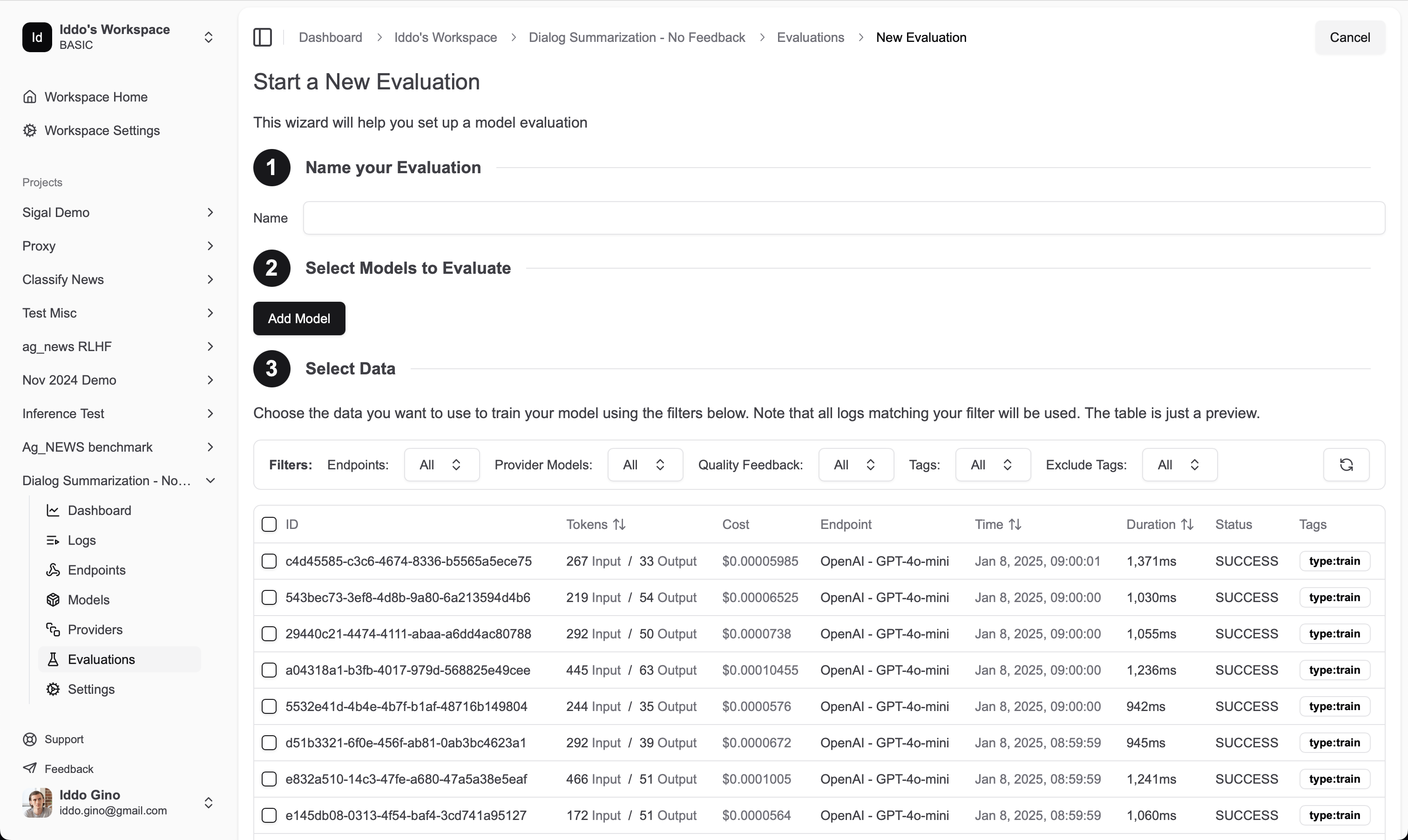
- Name: A name for your evaluation. This is for your reference and will be displayed in the dashboard.
- Models: The models you want to evaluate. You can select multiple models from the same provider or different providers. (note that models you train must be deployed before they can be evaluated)
- Data: Select the logs you want to use for evaluation. You can use tags and other filters to select the logs you want to use.
- If you are training custom models, you may want to reserve some logs for evaluation to ensure you are not testing on the same data you trained on. You can do this by tagging some logs with
testand excluding them from the training data when you initiate a model training. - If you have feedback for your logs, you should filter for positive (👍) logs to evaluate against.
- If you are training custom models, you may want to reserve some logs for evaluation to ensure you are not testing on the same data you trained on. You can do this by tagging some logs with
- Maximum Sample Count: The maximum number of samples to use for evaluation. This is useful if you have a large dataset and want to limit the number of samples used for evaluation.
- Evaluators: Select the evaluation functions you want to use. You can select multiple evaluation functions to get a comprehensive view of model performance. You can easily use our built-in evaluation functions, or you can create your own custom evaluation functions using code or LLM prompts (LLM as Judge). See the full list of available evaluation functions below.
Viewing evaluation results
Once you’ve created an evaluation, you can view the results in the evaluation details page. Here you’ll see a summary of the evaluation, including the evaluation function used, the number of samples evaluated, and the evaluation metrics. You will also be able to see individual responses from each model and compare them side-by-side.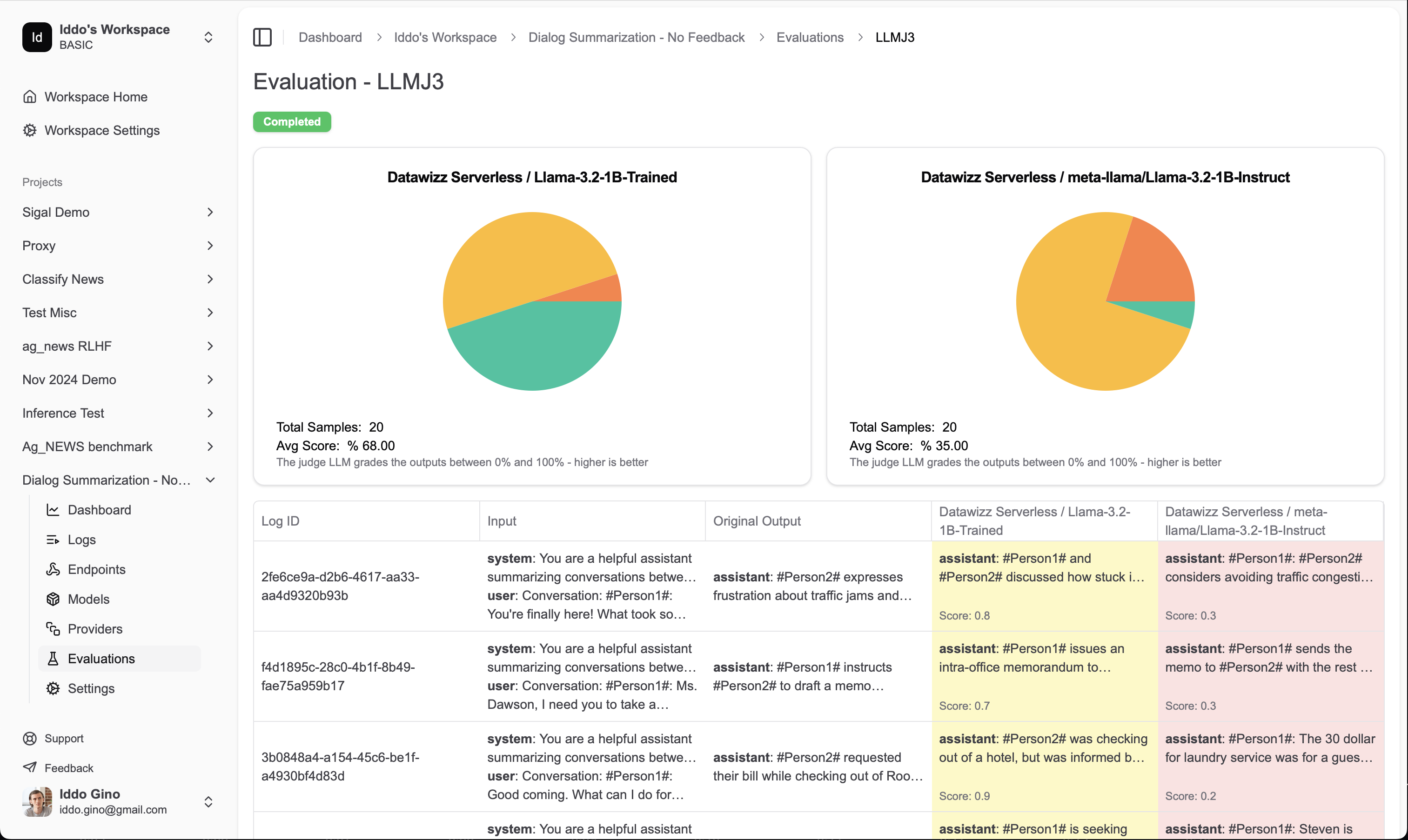
Custom Evaluators
You can define custom evaluation functions to suit your specific needs. Datawizz supports two types of custom evaluators:- Code Evaluators: Python-based evaluators that give you full programmatic control
- LLM as Judge Evaluators: Prompt-based evaluators that leverage language models Learn how to create custom evaluators in the Custom Evaluators section.