Many LLMs are limited to processing text, and in some cases images and audio (multi-modal models). Datawizz extends these native LLM capabilities by allowing you to send additional file types to these LLMs. Datawizz performs pre-processing to convert these files into content understandable by the LLMs.
For instance, with videos - Datawizz can extract frames, audio channels and transcription to provide a rich set of data to the LLMs. Similarly, office documents and PDFs can be converted into markdown for the LLMs to process.
Video Inputs
Datawizz makes it easy to send videos to the LLMs and have them reason about the content of the video.
- Source: Datawizz supports downloading videos from URLs, including services like YouTube, Vimeo, TikTok and more.
- Proxy: Datawizz can also use resedential proxies automatically to download videos from these services.
- Processing: Datawizz extracts frames, audio and transcriptions from the video. You can configure the number of frames to extract, the audio channels to process and the transcription settings.
- flexibility: this processing is compatible with all LLMs - you can select the LLM you want to use for reasoning about the video content.
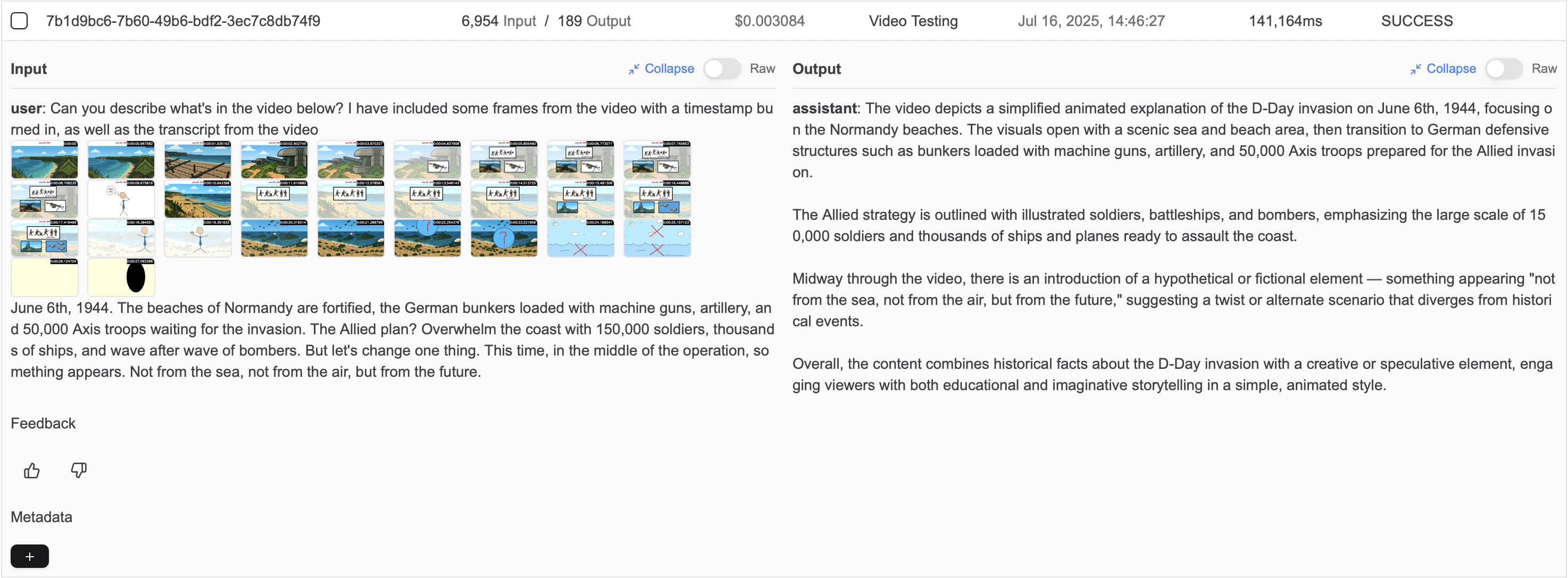 Log view of a video processing request, where you can see the frames + transcript sent to the LLM
Log view of a video processing request, where you can see the frames + transcript sent to the LLM
Sending Videos
To send a video attachment, you can send it as a part of a message to the LLM (similar to sending images with the OpenAI API):
Configurations
Alongside the video URL, you can specify additional configurations to control how the video is processed:
Detail Levels
The detail_level parameter allows you to control the resolution of the frames sent to the LLM. The available options are:
low: 512 pixels (longest side)medium: 768 pixels (longest side)high: 1024 pixels (longest side)
Most LLMs charge images based on their resoliution, so you can use this parameter to control the cost of processing the video. The default is None, which means the frames will be sent at their original resolution.
Prompting for Videos
Datawizz will automatically replace the video_url message part with image message parts (and potentially a text part for the transcript) when sending the request to the LLM. Your prompt need to explain to the LLMs that these are frames from the video, and that the transcript is a transcription of the audio in the video.
For exampple, you can use the following prompt:
This will result in an LLM request that looks like this:
You can combine video processing with other LLM features like structured output to generate structured insights from your video. If using timestamps, you can use structured output for event identification in videos
Document Inputs
Datawizz can process a wide variety of document types, including PDFs, office documents (Word, Excel, PowerPoint) and more. These documents are converted into markdown format for the LLMs to process.
Datawizz uses Microsoft’s MarkItDown library to convert these documents into markdown, which is then sent to the LLMs for processing.
Sending Documents
To send a document attachment, you can send it as a part of a message to the LLM (similar to sending images with the OpenAI API):
Configurations
Alongside the document URL, you can specify additional configurations to control how the document is processed: